What’s in the interview? Well, a whole lot of background stuff about my own move from London up to Cumbria, as well as something about my writing history and the transition from ancient history to science fiction… and back again.
Kindle Cover – Half Sick of Shadows
The immediate trigger for the interview was when Anastasia read Half Sick of Shadows, and we talk a little bit about that book in the midst of other things.
As an extra incentive, my historical fiction series (In a Milk and Honeyed Land, Scenes from a Life, and The Flame Before Us), together with two of my science fiction books (Far from the Spaceports, and Timing) are on Kindle Countdown deals this week, with price dropped to £0.99 and $0.99 on Amazon UK and US respectively. Navigate to http://www.kephrath.com/Extracts.aspx for some extracts from the historical series, or http://www.kephrath.com/ExtractsFuture.aspx for some from the speculative ones.
Finally, there’s a longish extract from what I am provisionally calling Quarry, which is my leap back into the even more remote past. Quarry explores the Langdale Axe factory and the people who lived and worked there – it’s at a very preliminary stage just yet, but hopefully as lockdown eases and life goes back to normal I shall have more time to develop it.
I read an article the other day – Magnetic Rivers Feed Star Birth – which I found interesting in its own right, but also provided a connection with a novel written in 1952 by Isaac Asimov, called The Currents of Space.
SOFIA in flight (NASA/ C. Thomas/ Max Planck Institute)
More about the novel in a while… first, the recent science research. This came about when a team of astronomers combined visual images from the (now retired) Spitzer Space Telescope with infra-red images from the SOFIA, the airborne Stratospheric Observatory for Infrared Astronomy. Both devices were pointed at the Serpens South star cluster, a region about 1400 light years from Earth, where stars are being formed.
The combination of these two generated the following image:
Composite image of the Serpens South star cluster, showing magnetic flowlines of star-forming material (NASA/ SOFIA/ T. Pillai/ JPL-Caltech/ L. Allen/ USRA)
The infra-red image showed where magnetic lines of force were aligning along “rivers” of material and funneling this into regions where stars are being actively formed. In the lower left region the magnetic flow is along these “rivers”, whereas in the top part of the image, they are perpendicular to the flow of matter. Sometimes magnetism and gravity reinforce each other: other times they are opposed. Where they are aligned, spatial currents enhance star formation.
Onto fiction, and Asimov’s book. Here, a particular planet – Sark – relies for its enormous wealth on a particular luxury fibre which grows only in one place – a subjugated vassal planet to Sark called Florina. A great deal of political manoeuvring has gone on to try and reproduce this fibre elsewhere, without success. In part, the book is exploring attitudes of colonialism and exploitation, but the science bit of the book has to do with the flow of minuscule quantities of elements through space. The central character has had his memory erased by the Sark government, since he had discovered that this elemental flow – the currents of space – was the root cause of the special fibre, opening the possibility of duplication elsewhere. Moreover, the same currents were driving Florina’s sun towards going nova.
So the real-world effect of matter flows through space – at least in the one case studied – is to help create stars, whereas in Asimov’s fictional universe, they were driving a star to destruction. That aside, both are exploring the same phenomenon, how the almost-vacuum of space nevertheless contains enough atoms to affect the development of stars nearby.
Fascinatingly, this tiny quantity of atoms, once distributed into space by stars which flare up or explode, forms the chemical basis for life. Long long ago, the tangible part of our universe consisted almost entirely of hydrogen, driven about by intense radiation, and pulled here and there by dark matter. All the heavier elements – including every single particle in our bodies – have been produced in the interior of stars, and then scattered nearby as these stars age and die. Some supernova explosions have brought to Earth the chemical constituents of life, and (according to recent research) others may have brought about some of the mass extinctions of life in Earth’s history. Matter currents in space can – in fact as well as fiction – bring both life and death.
The Crab Nebula, thought to be a supernova remnant from long ago (NASA, ESA, Alison Loll & Jeff Hester (University of Arizona))
Time is a funny thing, especially as regards our perception of the flow of time. The same objectively-measured period of time can seem unbearably slow to one person, and disappointingly fast to the next. But fundamentally, our perception of time has been fashioned by generations of human and pre-human ancestors growing up on planet Earth.
We have become very deeply, viscerally accustomed to the various time rhythms of this planet – the 24-hour light dark cycle which gives us days, the 28-day lunar cycle which gives us months, and the 365-day solar cycle which gives us years. There are, of course, longer cycles still, such as the 18-year lunar rising pattern – our prehistoric ancestors seem to have been aware of this, though most of us today have forgotten it. Living anywhere on the surface of the Earth other than the extreme polar regions, all life is given, and responds to, days, months, and years.
The Liminal Zone cover
So one of the questions I posed myself while writing The Liminal Zone was, what would life be like if those rhythms were absent? Pluto’s moon Charon doesn’t have this range of patterns. There is a cycle of about a week, during which Pluto and Charon revolve around their common gravitational centre. As they do this, the light from the distant sun shifts to give light and darkness – so a “day” is about a week on Charon. They are tidally locked to each other, presenting the same face to their partner just as our Moon does to us, so that the “day” and the “month” are the same. But beyond that, there is no natural cycle for future inhabitants to shape themselves around until you get to Pluto’s orbit around the sun – 248 Earth years long.
How would this absence of multiple cycles affect human experience out there? Right now, the short answer is that we do not know. I imagine that, at least at first, occupants would retain a nominal Earth-based cycle of 24-hour days, with weeks, months and years built up from there. But on some level, I suspect that the missing natural cues for these cycles would start to weigh on us.
Some readers of The Liminal Zone have commented that there is a slightly timeless aspect to the characters in the novel. They respond to, and act on, slowly changing patterns rather than the swift passage of events. An impression made at first meeting tends to freeze into a lasting reaction. If so, then this is exactly what I wanted. I believe that the absence of natural months and years (in the way we are intimately familiar with, here on Earth) would, little by little, soak into the lives and psyches of those people. In the end, the vast slowness of life in the Kuiper Belt, the liminal zone of the whole solar system, would prevail. As Elaine, one of the central characters, says of herself, “There is nothing more important than the recognition of patterns.” The hurry and bustle of weeks, days, hours, minutes, seconds, has yielded in her to an appreciation of how patterns once experienced tend to repeat themselves in different ways into the future. For her, those patterns are the stationary points in the apparent disorder of the cosmos: they are the situations she likes to recognise and gravitate towards.
Pluto and Charon in colour (NASA/Johns Hopkins University Applied Physics Laboratory/Southwest Research Institute)
In something of a departure, I used IngramSpark (IS) as my print-on-demand supplier for The Liminal Zone, rather than Amazon’s CreateSpace (CS), which I used for my previous novels. This was largely at the suggestion of my local bookshop, who indicated that they would, and do, order from IS, but wouldn’t order from CS. Presumably the connection with Amazon as a commercial threat is too close for comfort. Now, I’d read occasional comments from other authors that they had had problems with IS, in particular with refusal to accept pdf files on submission. As things turned out, I had no problems with the internal part (the manuscript itself) and only one problem, easily resolved, with the cover.
Now, readers of this blog will probably know that I am committedly geeky when it comes to generating manuscripts, and prefer to use a format method which is as close as possible to the one used by whatever software tool processes the manuscript. So for Kindle editions, I use HTML files, since that is what the Amazon tool kindlegen really prefers. Yes, it will accept other formats, and munch through them, but sometimes throws out formatting artefacts which are hard to resolve. By staying with HTML and similar files, I stay in control of the process. A typical kindlegen project looks like this:
opf file – the overall controller file providing metadata like ISBN, keywords, description, etc, and identifying other components
multiple HTML files for the front and back matter, a contents page, and individual chapters
a stylesheet determining how things look
a cover image, in jpg or png format
other interior images, in any of several formats
an ncx file, which is equivalent to a table of contents but feeds in to the kindle hardware navigation, rather than being presented to the user inside the book
If you are so motivated, you can gather different elements in their own sub-folders inside the main project folder, just so long as the opf file points to the correct location.
This structure has lots of advantages – first, it appeals to the programmer in me, who likes things to be laid out in a systematic and atomic manner, consistently between projects. Secondly, I can at any time generate a kindle version and deploy it to a real device, so I can catch layout weirdness early on, and also test out different viewing options that a reader might prefer. That’s hard to do if you just write in Word or a similar package. Finally, I can put placeholder content in at roughly the right location – for example my cover image for ages was nothing like the splendid one I ended up with, but was a rather boring image of the right dimensions. Likewise, I could work on sections at any point in the book, carry out edits, or simply tidy up the front and back matter if I felt lacking in inspiration.
What about the paperback? IS, just like CS and presumably every other print-on-demand supplier, wants to get from you a properly formatted pdf file which adheres to specific industry standards. And here is where some folk run into problems. It is entirely possible to generate pdf files from pretty much any program you choose – Word, Notepad, and so on – simply by selecting the print-to-pdf option in your menu. However, it turns out that individual software teams are not always as careful as they might be about the compliance of their print-to-pdf commands. Sure, you get something which will display in a web page, or whatever, but when given to something more particular about standards – like the IS submission process – things do not always come out right.
The Liminal Zone Paperback Cover
So I don’t use Word – instead I use an online tool which turns out pdf files which adhere to the relevant standards. The one I use is now called Overleaf (formerly ShareLatex) and was originally designed to help university staff and students to get their papers, dissertations, and whatever, correctly laid out. It is based on a text layout engine called latex, which contains all kinds of support for mathematical equations and the like – which I don’t need – but in particular allows settings for page size, running headers and footers, correct location of new chapters, font and style support, and such like. Even better, it is based on a project layout which is directly parallel to my Kindle layout above. The files have a .tex extension rather than .htm or .html, and there is no equivalent to the ncx file, but in other respects it all maps across.
Which is great – when I get to the stage of wanting a paperback version, I reproduce my Kindle project layout in a new Overleaf project, then copy across the text from my source files into the corresponding tex file, compile the whole, and voila… one standards-compliant pdf file. Now, that then generates a whole lot of additional work to check that characters are not spilling too far into the margins, and that widow and orphan lines are taken care of. Those edits have to be back-copied into the Kindle version. But it’s all very neat and orderly, and not only leaves me with a sense that all is properly organised, but also that the results are gong to be accepted first time. Which they were!
I mentioned that there was one small issue with the cover – this was a technical one relating to the use of what pdf standards designers call colour profiles. Basically these are a neat way to reduce file size by appealing to a commonly agreed list of colour mappings. It’s a great idea, but IS require cover files which don’t use them. Workaround – resave the file without the profile information, and accept the larger file size.
All in all, my experience with IS has been uniformly positive, and I would certainly choose them again.
Well, it’s almost time for The Liminal Zone to see the light of day. The publication date of the Kindle version is this Sunday, May 17th, and it can already be preordered on the Amazon site at https://www.amazon.co.uk/dp/B087JP2GJP. The paperback version will not be too far behind it, depending on the final stages of proofing and such like. I am, naturally, very pleased and excited about this, as it is quite a while since I first planned out the beginnings of the characters, setting and plot. Since that beginning, some parts of my original ideas have changed, but the core has remained pretty much true to that original conception all the way through.
But I thought for today I’d talk a little bit about my particular spin on the future development of the solar system. My time-horizon at the moment is around 50-100 years ahead, not the larger spans which many authors are happy to explore. So readers can expect to recognise the broad outlines of society and technology – it will not have changed so far away from our own as to be incomprehensible. I tend towards the optimistic side of future-looking – I read dystopian novels, but have never yet been tempted to write one myself. I also tend to focus on an individual perspective, rather than dealing with political or large-scale social issues. The future is seen through the lenses of a number of individuals – they usually have interesting or important jobs, but they are never leaders of worlds or armies. They are, typically, experts in their chosen field, and as such encounter all kinds of interesting and unusual situations that warlords and archons might never encounter. The main character of Far from the Spaceports and Timing (and a final novel to come in that trilogy) is Mitnash Thakur, who with his AI partner Slate tackles financial crime. In The Liminal Zone, the central character is Nina Buraca, who works for an organisation broadly like present-day SETI, and so investigates possible signs of extrasolar life.
Amazon Dot – Active
Far from the Spaceports, and the subsequent novels in the series, are built around a couple of assumptions. One is that artificial intelligence will have advanced to the point where thinking machines – my name for them is personas – can be credible partners and friends to people. They understand and display meaningful and real emotions as well as being able to solve problems. Now, I have worked with AI as a coder in one capacity or another for the last twenty-five years or so, and am very aware that right now we are nowhere near that position. The present-day household systems – Alexa, Siri, Cortana, Bixby, Google Home and so on – are very powerful in their own way, and great fun to work with as a coder… but by no stretch of the imagination are they anything like friends or coworkers. But in fifty, sixty, seventy years? I reckon that’s where we’ll be.
Xenon ion discharge from the NSTAR ion thruster of Deep Space 1 (NASA)
The second major pillar concerns solar system exploration. Within that same timespan, I suggest that there will be habitable outposts scattered widely throughout the system. I tend to call these domes, or habitats, with a great lack of originality. Some are on planets – in particular Mars – while others are on convenient moons or asteroids. Many started as mining enterprises, but have since diversified into more general places to live. For travel between these places to be feasible, I assume that today’s ion drive, used so far in a handful of spacecraft, will become the standard means of propulsion. As NASA says in a rather dry report, “Ion propulsion is even considered to be mission enabling for some cases where sufficient chemical propellant cannot be carried on the spacecraft to accomplish the desired mission.” Indeed. A fairly readable introduction to ion propulsion can be found at this NASA link.
I am sure that well before that century or so look-ahead time, there will have been all kinds of other advances – in medical or biological sciences, for example – but the above two are the cornerstones of my science fiction books to date.
That’s it for today, so I can get back to sorting out the paperback version of The Liminal Zone. To repeat, publication date is Sunday May 17th for the Kindle version, and preorders can be made at https://www.amazon.co.uk/dp/B087JP2GJP. As a kind of fun bonus, I am putting all my other science fiction and historical fiction books on offer at £0.99 / $0.99 for a week starting on 17th.
Before starting this blog post properly, I should mention that my latest novel in the Far from the Spaceports series – called The Liminal Zone – is now on pre-prder at Amazon in kindle format. The link is https://www.amazon.co.uk/gp/product/B087JP2GJP. Release date is May 17th. For those who prefer paperback, that version is in the later stages of preparation and will be ready shortly. For those who haven’t been following my occasional posts, it’s set about twenty or so years on from the original book, out on Pluto’s moon Charon, and has a lot more to do with first extraterrestrial contact than financial crime!
Amazon Dot – Active
Back to this week’s post, and as a break from the potential for life on exoplanets, I thought I’d write about AI and its (current) lack of common sense. AI individuals – called personas – play a big role in my science fiction novels, and I have worked on and off with software AI for quite a few years now. So I am well aware that the kind of awareness and sensitivity which my fictional personas display, is vastly different from current capabilities. But then, I am writing about events set somewhere in the next 50-100 years, and I am confident that by that time, AI will have advanced to the point that personas are credible. I am not nearly so sure that within the next century we’ll have habitable bases in the asteroid belt, let alone on Charon, but that’s another story.
What are some of the limitations we face today? Well, all of the best-known AI devices, for all that they are streets ahead of what had a decade ago, are extremely limited in their capacity to have a real conversation. Some of this is context, and some is common sense (and some other factors that I’m not going to talk about today).
Context is the ability that a human conversation partner has to fill in gaps in what you are saying. For example, if I say “When did England last win the Ashes?“, you may or may not know the answer, but you’d probably realise that I was talking about a cricket match, and (maybe with some help from a well-known search engine) be able to tell me. If I then say “And where were they playing?“, you have no difficulty in realising that “they” still means England, and the whole question relates to that Ashes match. You are holding that context in your mind, even if we’ve chatted about other stuff in the meantime, like “what sort of tea would you like?” or “will it rain tomorrow?“. I could go on to other things, like “Who scored most runs?” or “Was anybody run out?” and you’d still follow what I was talking about.
I just tried this out with Alexa. “When did England last win the Ashes?” does get an answer, but not to the right question – instead I learned when the next Ashes was to be played. A bit of probing got me the answer to who won the last such match (in fact a draw, which was correctly explained)… but only if I asked the question in fairly quick succession after the first one. If I let some time go by before asking “Where were they playing?“, what I get is “Hmmm, I don’t know that one“. Alexa loses the context very quickly. Now, as an Alexa developer I know exactly why this is – the first question opens up the start of a session, during which some context is carefully preserved by the development team deciding what information is going to be repeatedly passed to and fro as Alexa and I exchange comments. During that session, further questions within the defined context can be handled. Once the session closes, the contextual information is discarded. (If I was a privacy campaigner, I’d be very pleased that it was discarded, but as a keen AI enthusiast I’m rather disappointed). With the Alexa skills that I have written (and you can find them on the Alexa store on Amazon by searching for DataScenes Development), I try to keep the fiction of conversation going by retaining a decent amount of context, but it is all very focused on one thing. If you’re using my Martian Weather skill and then assume you can start asking about Cumbrian Weather, on the basis that they are both about weather, then Alexa won’t give you a sensible answer. It doesn’t take long at all to get Alexa in a spin – for some humour about this, check out this YouTube link – https://www.youtube.com/watch?v=JepKVUym9Fg…
So context is one thing, but common sense is another. Common sense is the ability to tap into a broad understanding of how things work, in order to fill in what would otherwise be gaps. It allows you to make reasonable decisions in the face of uncertainty or ambiguity. For example, if I say “a man went into a bar. He ordered fish and chips. When he left, he gave the staff a large tip“, and then say “what did he eat?“, common sense will tell you that he most likely ate fish and chips. Strictly speaking, you don’t know that – he might have ordered it for someone else. It might have arrived at his table on the outdoor terrace but was stolen by a passing jackdaw. In the most strict logical sense, I haven’t given you enough information to say for sure, and you can concoct all kinds of scenarios where weird things happened and he did not, in fact, eat fish and chips… but the simplest guess, and the most likely one that you’d guess, is that is what he did.
In passing, Robert Heinlein, in his very long novel Stranger in a Strange Land, assumed the existence of people whose memory, and whose capacity for not making assumptions, meant that they could serve in courts of law as “fair witnesses”, describing only and exactly what they had seen. So if asked what colour a house was, they would answer something like “the house was white on the side facing me” – with no assumption about the other sides. All very well for legal matters, but I suspect the conversation would get boring quite quickly if they carried that over into personal life. They would run out of friends before long…
Now, what is an AI system to do? How do we code common sense into artificial intelligence, which by definition has not had any kind of birth and maturation process parallel to a human one (there probably has been a period of training in a specific subject). By and large, we learn common sense (or in some people’s case, don’t learn it) by watching how those around us do things – family, friends, school, peers, pop stars or sports people. And so on. We pick up, without ever really trying to, what kinds of things are most likely to have happened, and how people are likely to have reacted, But a formalised way of imparting common sense has eluded AI researchers for over fifty years now. There have been attempts to reduce common sense to a long catalogue of “if this then that” statements, but there are so many special cases and contradictions that these attempts have got bogged down. There have been attempts to assign probabilities of particular individual outcomes, so that a machine system trying to find its way through a complex decision, would try to identify what was the most likely thing to do in some kind of combination problem. To date, none have really worked, and encoding common sense into AI remains a challenging problem. We have AI software which can win Go and other games, but cannot then go on to hold an interesting conversation about other topics.
All of which is of great interest to me as author – if I am going to make AI personas appear capable of operating as working partners and as friends to people, they have to be a lot more convincing than Alexa or any of her present-day cousins. Awareness of context and common sense goes a long way towards achieving this, and hopefully, the personas of Far from the Spaceports, and the following novels through to The Liminal Zone, are convincing in this way.
Tatooine’s two suns (Twentieth Century Fox/LucasFilm via LiveScience.com)
In the last couple of blogs, I have talked about exoplanets, what kind of stars they circle around, and what the prospects are for life and story-telling. Today I want to pick out some oddities, to show that alien solar systems are very varied. Old-school planetology made out that the only kinds of solar system that made sense were ones that looked remarkably like our own – now, with the benefit of real data, we can see that that was an extremely parochial view. Let’s start with a classic Star Wars view… the two suns of Tatooine, where Luke Skywalker grew up. This is in fact not just a theoretical or film problem – the majority of stars you can see with the naked eye as you look out at night are in fact binaries (or members of higher multiples), so that single-star solar systems like are own are in fact in the minority.
This view requires that the planet find a stable orbit in a binary star system – no mean feat, as there are a lot of orbits which are unstable and end up with the planet being roasted or frozen at some point in its orbit. Indeed, the “three-body problem” – three sizeable objects moving under each other’s mutual gravity – is one which has proved to have no general solution, despite many years’ work. But it does have some approximate solutions, which can be worked on by computer simulation.
For example, you can imagine a planet in a very wide orbit, with the two suns circling each other at the centre. This could work, though perhaps the planet would end up outside the Goldilocks Zone, and so be inhospitably cold for life to develop comfortably. But in such a case, the suns would always look comparatively close to each other, and you could never have a situation where one sun would be setting as the other was rising.
Another extreme case is where the two suns are much further apart, and the planet orbits just one of them. If the distance between the two suns is large enough compared to the sun-planet distance, then this can also be stable. The view from such a planet’s surface would be quite different to the first case. The two suns could be at any angle relative to each other, and your view from the surface would vary between the two appearing close together, right through to being diametrically opposite, with periods of no night-time.
Of course, there’s nothing to stop a solar system built around binary stars being more complex again, with a mixture of some planets circling one or other of the suns, and others circling both of them as a central object much wider out. The more objects in the system, the more likely it is that orbits will not be stable in the long term, but it would make an interesting place to settle for a while. After all, orbital instability is usually a problem only over millennia or longer timescales.
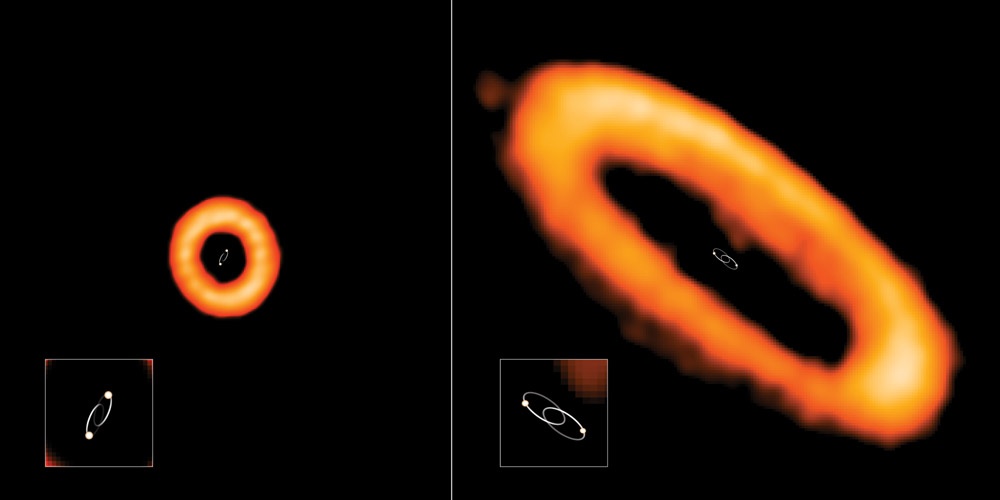
It’s natural to assume – as I did for the diagrams above – that the orbital plane of the planet(s) is the same as that of the suns. But in fact, recent observations from an observatory in Chile suggest that this probably is not always the case. That observatory is not yet capable of spotting individual planets, but it can detect the discs of matter circling stars, from which planets may well coalesce in time to come. And the disc certainly does give information about the orbital plane of subsequent planets. The following two pictures give a good idea of their contrasting results – stars which are close together and hence orbit quickly, tend to have a planetary disc aligned with the suns’ plane – this is the right-hand case below. Conversely, stars which are far apart and orbit slowly, tend to have the planetary disc misaligned. The views from planets in such systems would be constantly changing as the planets rose above and dipped below the solar plane.
Misaligned (left) and aligned (right) orbital planes (ALMA (ESO/NAOJ/NRAO), I. Czekala and G. Kennedy; NRAO/AUI/NSF, S. Dagnello via ScienceAlert.com)
Another curious situation has been seen with the star HD 158259, which is 88 light-years from us , and a little larger than our sun. Six planets have been observed in this system – one like an oversized Earth, and the others like undersized Neptunes. But the remarkable thing about this system is that it shows very neat gravitational resonance. I’ve written about this before – over a period of time mutual gravitational attraction tends to make orbits end up showing regular patterns. In the case of HD 158259 all the planets’ orbits are in the simple geometric ratio 3:2 to each other – each planet carries out 2 orbits while the next one towards the sun carries out three. This happens to be the same as Neptune and Pluto in our solar system, but our other planets don’t show this to anything like the same extent. How, I wonder, would astronomers on such a world, building their first telescopes and looking out at their family of planets, start to understand and rationalise this remarkable degree of ordeliness?
Finally, I should mention a discovery made from data acquired by the Kepler telescope and recently analysed (a couple of people have reminded me about this, and it’s well-worth including here. The exoplanet Kepler-1649c orbits its small red dwarf star within the system’s Goldilocks Zone. It’s almost precisely the same size as Earth and receives about 3/4 of the light that our Earth receives from the Sun. Now, it’s about 300 light-years from us, so we won’t be visiting it anytime soon, but it is, so far, the most similar exoplanet to Earth that we have observed. One of the researchers said “The more data we get, the more signs we see pointing to the notion that potentially habitable and Earth-size exoplanets are common around [red dwarf] stars”.
Artist’s impression, exoplanet circling red dwarf (NASA/Ames Research Center/Daniel Rutter)
Which is all great for story-telling, since there are a great many red dwarfs much closer to us than 300 light-years.
For my own fictional take on all this, The Liminal Zone will be available very soon…
This week I am carrying on thinking about exoplanets – planets which we have detected circling other stars. In modern science fiction, this helps us decide the parameters we are putting on life which originated elsewhere.
Light intensity variation as an exoplanet passes in front of its star (Space Telescope Science Institute, via WIki)
It’s worth saying, in passing, that there are several ways we detect such planets, bearing in mind that they are so small as to be normally drowned out in the light of the primary star they orbit. Two are particularly common. The first of these is to accurately measure the path of that primary star through space, and map out small wiggles to that path as the planet(s) in its solar system orbit around it. The second is to accurately measure the light shining from the star, and detect periodic decreases in intensity as the planet(s) pass in front of it. Both ways work best if the orbital plane of the planet is aligned with the direct line between Earth and the star. That means that, at present, our best techniques are unable to give confident results about a great many possible candidates – a star which does not periodically dim might not have a planet, or it might have one whose orbital plane is at a different angle.
Hertzsprung-Russell diagram – our sun is the yellow dot (U Oregon web site)
Now, in the early days of this search, the main focus was on stars which are broadly the same as our sun – stars which are roughly in the middle of the typical path of stellar evolution known as the Hertzsprung-Russell diagram. In this diagram, dimmer stars are towards the bottom and brighter ones towards the top. Hotter stars are to the left and cooler ones to the right. So early researchers picked out stars that were broadly like ours, on the grounds that the conditions on planets there would most likely be ones which we would recognise – a kind of Goldilocks test.
Now, as time has gone on, we have found planets circling all kinds of stars, and our thinking about which ones might be most congenial for life has changed a bit. The most common type of star in the galaxy – so far as we can tell by sampling our neighbourhood as best we can – is a red dwarf. Red dwarfs sit near the bottom right hand corner of the HR diagram – they are low intensity, and also quite cool. Of course, “cool” is a relative thing – their surface temperature is still typically anything from 2000 to 3500 degrees. To give an idea of their ubiquity, the nearest star to the Sun is a red dwarf, as are fifty of the sixty nearest stars. Red dwarfs may make up three-quarters of the stars in our galaxy. We don’t tend to notice them because they are so very dim – not one of those fifty stars is visible to the naked eye, though if you know exactly where to look, a good pair of binoculars or a small telescope can pick some of them out.
Artist’s impression – planet with moons circling a red dwarf (NASA)
But if you are on the search for extra-solar life, red dwarfs are a good place to start. For one thing, a great many of them have planets circling them. The several different exoplanet mapping telescopes, both on Earth and in orbit, regularly find such solar systems. The star is cool, so the Goldilocks Zone in which surface water can exist is much closer to the star than the one in our own system – but it does exist, and a reasonable proportion of red dwarfs have at least one planet in the zone. Red dwarfs are also extremely long-lived – rather longer than our sun – which would give life an opportunity to develop. On the flip side, some red dwarfs appear to have regular flares, which would tend to be inimical to life.
How, one wonders, would a life form develop on a planet around a red dwarf star? Sunshine would be more orange than yellow, but since we are in the Goldilocks Zone, the daytime temperatures would be much the same. In terms of size, a red dwarf is vastly smaller than our sun – some are around the size of Jupiter. However, because the potentially habitable planets are so much closer, it would appear substantially larger in the sky – perhaps five times the diameter.
The Moon as seen from the Earth – tidal locking means that we never see the other side (Wiki)
It is thought that many planets orbiting red dwarfs may be tidally locked – presenting the same face towards their primary. We are familiar with this regarding the view of our Moon from the Earth – we only see one side, and the other is forever hidden from us. At the moment the earth is not tidally locked to the Moon – we see it move around us through night and day – but in the very remote future this will probably happen. When a planet is tidally locked to its sun, then only one side of the planet receives light and warmth. Air and water circulation will tend to distribute the heat around the globe, but nevertheless there will tend to be extremes. Could life spring up and develop towards complexity and society in these conditions? My guess is yes, though it’s a question that has yet to be answered.
Finally, I am very happy to say that The Liminal Zone is now finished, and I am going through the process of preparing both kindle and paperback versions of it. Will a red dwarf feature in it? You’ll have to wait and see…
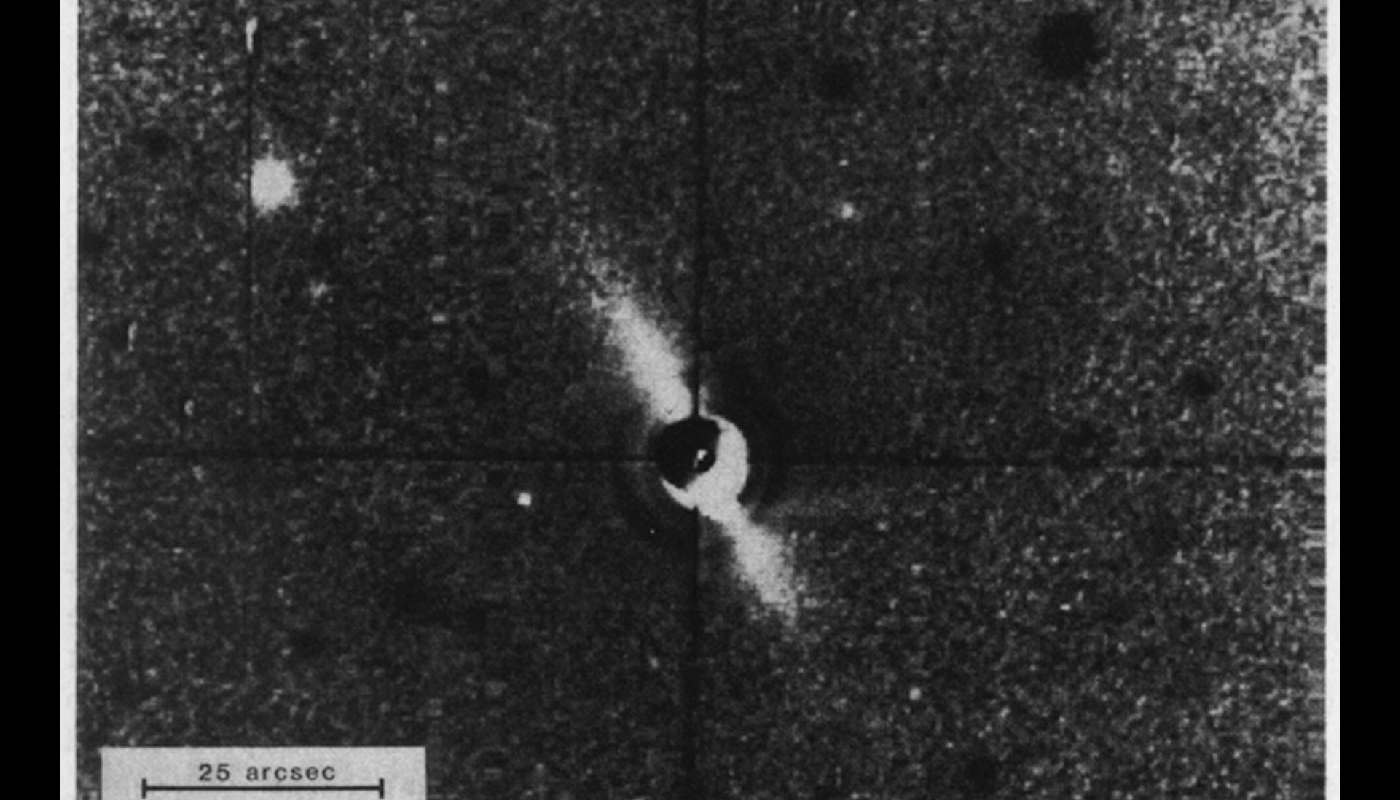
Writing The Liminal Zone has had me thinking a lot about exoplanets – planets beyond our solar system. Now, before 1992 we had no definite confirmation that any such planets existed. There had been lots of speculation, and majority opinion was certainly that we would find them… sometime… but no actual proof yet existed. So science fiction stories had to rely heavily on invention. The first breakthrough came in 1984, with the first photograph of a planetary ring of debris surrounding a star – Beta Pictoris, visible from the southern hemisphere.
Disk of dust and gas around Beta Pictoris,, April 1984 (Bradford A. Smith, Richard J. Terrile, NASA)
This picture transformed expectations about other stars – astronomy had reached a point where not just stars, but details of their immediate environment could be explored and talked about. The discovery of extra-solar planets (soon exoplanets) was only a matter of time. And with that prospect, the debate about life emerging in other systems could start to be built on some real content. And, moreover, science fiction could start to use real data rather than just speculation and extrapolation.
The Hubble telescope launched in 1990, and within two years the first such planets were announced. To be sure, these were orbiting a pulsar, and the levels of radiation they experienced meant that nobody expected them to harbour any kind of life. But before the year 2000, discoveries were announced of planets circling what you might call “normal” stars, as well as systems with multiple planets. Indeed, in the three decades since Hubble was launched – to which were added a series of other observation platforms, notably Kepler – we have clocked up over 4000 such planets.
Kepler is launched (NASA)
With such an excess of riches to be found, the problem quickly became one of classification. It was not just a matter of finding more planets – were they large and gaseous (like Jupiter)? Or small and rocky (like Earth)? Or not like any particular planet in our own solar system? How closely did they orbit their primary? The idea of a Goldilocks Zone – not too hot, not too cold, but just right – rapidly became popular.
We generally think of this zone as the one in which, on a planet’s surface, water neither boils nor freezes. Some people split it into two internal volumes – a “conservative zone“, where conditions are more perfect, and an “optimistic zone“, in which conditions are closer to the edge. In our solar system, Earth is (of course) within the conservative zone, Mars is at the boundary between conservative and optimistic, and Venus is reckoned to be too close to the sun to be in even the optimistic zone. The size of such a zone depends critically on the brightness and heat output by the sun in question: the following picture shows that many planets do in fact fit this description (though they might be inimical to life for other reasons, such as intensity of radiation, or sheer mass).
Variation of Goldilocks Zone with the brightness of the sun (Chester Harman via Wiki)
However, some biologists challenge this idea on the grounds that it is too simplistic. The surface temperature of a planet gives a poor reflection of the places within it that life can exist. On our Earth, we have found life in the freezing conditions of Antarctica, beside underwater hot vents, and nestling within cracks and fissures in rocks at all temperatures. Once life has gained a foothold on a planet, it seems able to adapt to any manner of diverse situations – the open question is whether it needs some more ideal conditions to begin with. Within our own solar system, the search for life has shifted focus from the planets which most obviously resemble our own – Mars and Venus – to planets and moons which show evidence of having sub-surface oceans. Indeed, 6 such worlds contain more water (including ice) than Earth does – Europa, Pluto, Triton, Callisto, Titan, and Ganymede, in increasing order of water+ice content. All of these are well beyond the outer edge of the optimistic zone, but each may well support life, in its own way. So the Goldilocks Zone, whilst comparatively simple to understand and assess, may well not give the full story.
Comparison of Earth and Ganymede – total volume and water volume (Jenny Cheng and Skye Gould/Business Insider)
Over the next couple of weeks, I shall be looking at some possible locations for extra-solar life which differ from those we enjoy here. In the early days of exoplanet hunting, the search focused on suns closely resembling our own sun – but now other kinds of star are regularly studied – red dwarfs, binary stars, and so on. And by the time we get to the end of this series, there might well be another extract from The Liminal Zone.
Pluto as seen by New Horizons (NASA/JHUAPL/SwRI/Alex Parker)
I’ve blogged before about how Pluto – orbiting between 30 and 50 times as far from the sun as our Earth, and so receiving at best one thousandth of the radiant energy from the Sun – has proved to be a hugely interesting place to explore. This is in stark contrast with old science-fiction books, which dismissed Pluto as a featureless frozen lump with no real attraction to spacefarers. The data returning from NASA’s New Horizons probe, which is still being pored over and analysed, has changed all that, revealing Pluto and its major moon, Charon, as fascinating worlds in their own right.
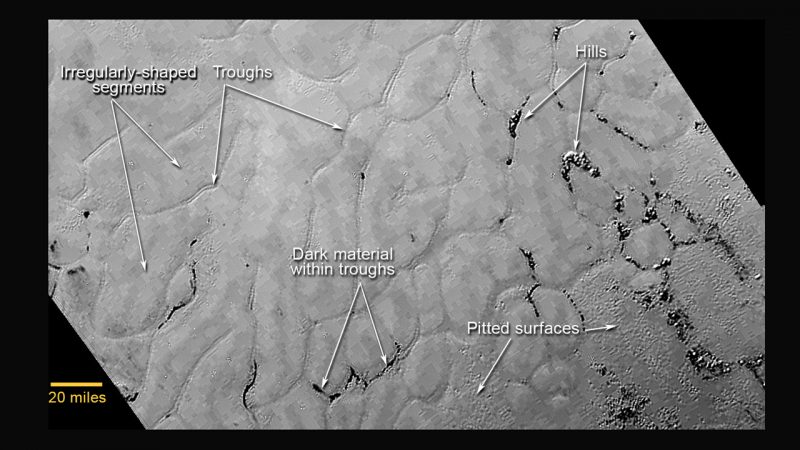
There has been some evidence before now, that Pluto might have an ocean below its surface. For example, there were pictures like the one below, showing that the smooth region of Sputnik Planitia (the white region shown above, just right of centre) has surface details which look for all the world like an ice skin over liquid. In addition, the layer of ice across the surface is thinner here than the average across Pluto.
Detail of Sputnik Planitia, showing cells divided by troughs (NASA/JHUAPL/SwRI)
Now, several other bodies out in the distant reaches of the solar system do have oceans – the best known being Europa – but typically these are on moons orbiting one or other of the giant planets. Europa, for example, is Jupiter’s fourth-largest moon. In these cases, the gravity of the planet causes tides which constantly flex the moon. This flexing in turn causes internal heat, and so the liquid remains liquid rather than freezing solid. Pluto has no such planet to orbit around, and the mechanism by which a sub-surface ocean might stay liquid was unknown.
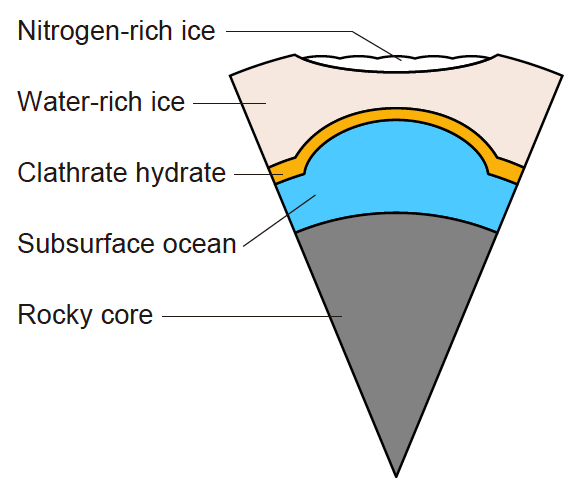
Two recent pieces of research have strengthened the idea, and provided a suggestion of just how the ocean might stay liquid. First, scientists studying the part of Pluto diametrically opposite to Sputnik Planitia noticed black “ripples” of rock where the surface had been thrown into a turmoil which it is hard to imagine. According to the survey, another rock, about 250 miles across, collided with Pluto some long time ago, creating the Sputnik region. The shock waves then travelled both around Pluto’s surface and through its interior, ending up focused on the opposite side as though through a lens. Such shock waves travel fast through a planet’s rocky core, more slowly around the surface layer, and slower still through a sub-surface ocean. The role of the ocean is clear: for these different types of wave to coincide on the opposite side, the fast transit through the core is balanced with the slow one through liquid, ending up at the target at the same time as the medium ones around the surface.
The proposed interior of Pluto (Kamata S. et al., Nature Geosciences)
So, how would the liquid remain liquid over long spans of time? The clue here comes from some computer simulations made by a joint Japanese-American team, in which they study the most likely scenario which remains consistent with other facts we know about Pluto. They suggest that a thin layer of chemicals called hydrates (crystalline solids resembling water ice) would act as an insulating blanket, keeping the liquid warm enough not to freeze. The hydrate layer is based on methane, which would rise up from Pluto’s core and collect at this level of the planet.
An ocean on (or, rather, under) Pluto is surely one of the least expected outcomes of the New Horizons’ observations. As we find steadily larger numbers of exoplanets beyond our own solar system, it is worth wondering – if Pluto of all places can maintain an ocean, then how many more ocean planets and moons might there be out there?
Meanwhile, the release date for my next novel, The Liminal Zone, is getting closer. It’s the next in the Far from the Spaceports series, but set a couple of decades later, when the joint exploration of the solar system by people and AI personas has moved beyond the asteroid belt all the way out to Pluto’s moon Charon…